5 things I learned architecting AI systems that run tens of billions of inferences per day (That nobody shows in POC demos)
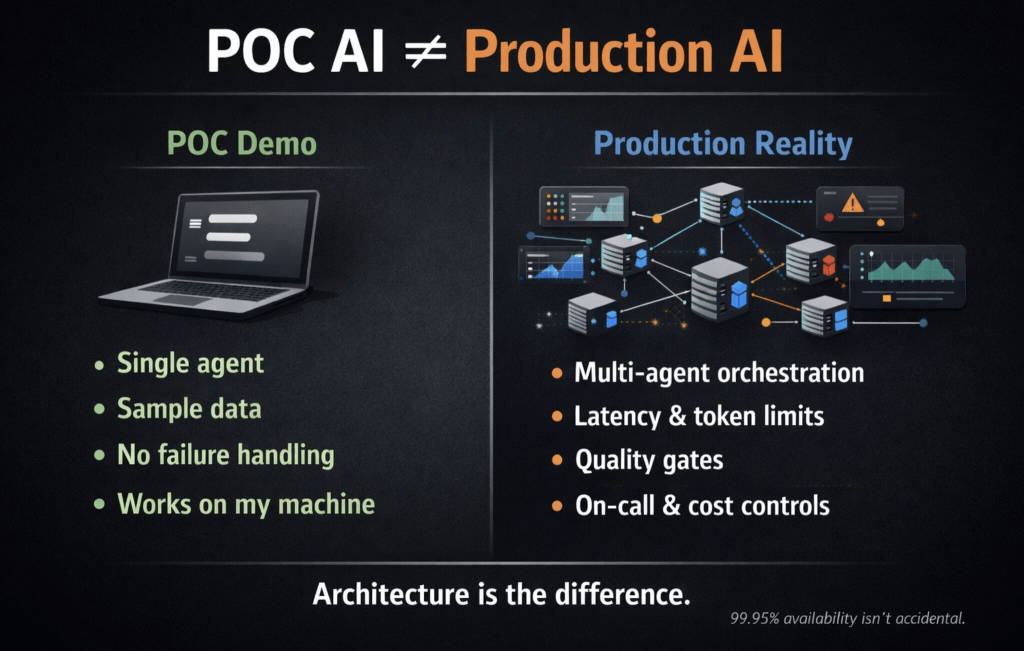
1) “It works in the demo” is the most dangerous sentence in enterprise AI
Most AI initiatives fail in production—not because the model is wrong, but because the architecture can’t survive reality: latency spikes, token limits, context window overflows, partial outages, and cascading failures.
Production isn’t a bigger demo. It’s an entirely different discipline.
2) Real enterprise value starts with multi-agent orchestration
Single-agent demos look impressive. Enterprise problems require 10–15 specialized agents coordinating across domains—with context handoffs, retries, isolation, and graceful degradation.
Designing agent-to-agent communication is 10× harder than building the AI itself.
3) Hallucination mitigation is an architecture problem, not a prompt problem
We implemented automated quality gates before responses reached users:
source verification, confidence scoring, and human-in-the-loop triggers.
This isn’t prompt tuning. It’s production engineering. Result: 97%+ accuracy across tens of millions of daily inference requests.
4) Cost optimization happens at the architecture layer At scale, token costs get brutal—fast. We reduced inference costs by ~40% using intelligent context pruning, hierarchical summarization, and caching strategies—not by switching to cheaper models.
The right architecture makes expensive AI sustainable.
5) The real gap isn’t technology—it’s production experience many AI architects can explain transformers and RAG pipelines.
Very few can explain what happens when:
• an agent crashes at 3 AM
• context windows overflow across a 15-agent workflow
• 10,000 users are waiting for a response
That’s not criticism. It’s the current market reality. Enterprise AI is maturing quickly. And a credibility gap is forming.
The question is no longer: “Can you build an AI demo?”
It’s: “Can you keep it running at 99.95% availability when the stakes are real?”

Leave a comment